Guide Shopify SEO le référencement naturel sur Shopify en 2026 : SEO et GEO
Ce guide démystifie le référencement naturel sur Shopify en s’appuyant sur des pratiques white-hat et durables. Il s’adresse à la fois aux débutants qui lancent leur première boutique, aux praticiens confirmés qui veulent affiner leur stratégie, et aux équipes e-commerce en phase de refonte.
Comprendre le CMS Shopify
Shopify est une solution SaaS qui permet de créer et exploiter rapidement une boutique en ligne sans lourd bagage technique. Son succès tient au time-to-market réduit, à un écosystème d’apps foisonnant et à une gestion intégrée (hébergement, paiement, inventaire). En 2026, la plateforme équipe des millions de sites et facilite le commerce omnicanal (vente en ligne, points de vente, connexions marketplaces).
Sur le plan SEO, ce positionnement a des implications : c’est un excellent choix pour des catalogues modérés et des équipes resserrées (lancement rapide, maintenance simple). En revanche, dès que les besoins deviennent très sur-mesure (règles d’indexation complexes, URLs atypiques, dépendance forte au trafic organique), les garde-fous techniques de la plateforme peuvent limiter la granularité souhaitée.
Le message clé : Shopify accélère l’exécution, mais exige une vigilance SEO continue pour compenser ce cadre fermé.
Shopify SEO : les atouts natifs
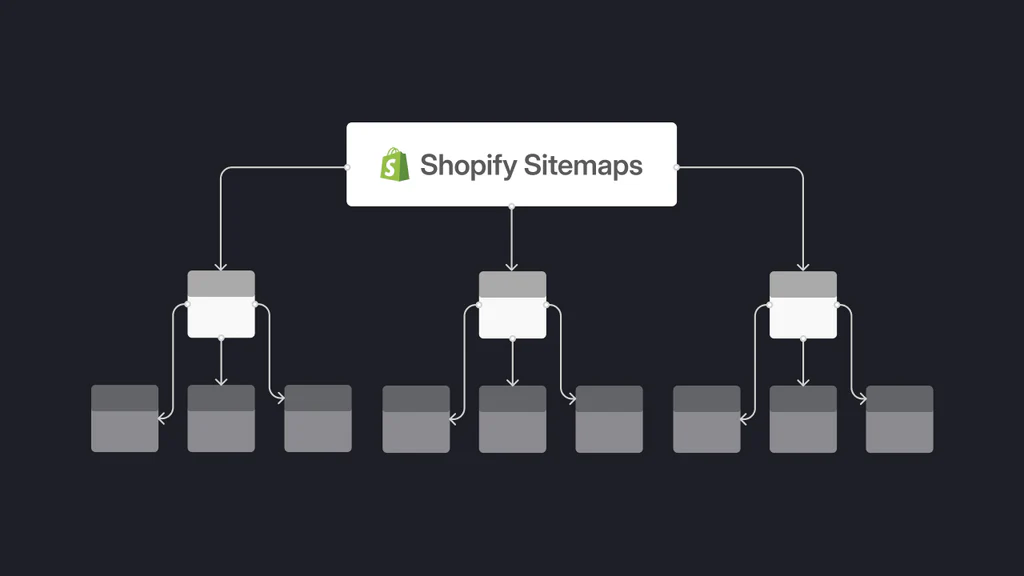
Sitemap : génération automatique, périmètre et bonnes pratiques
Le fichier sitemap.xml est généré automatiquement et se met à jour au fil des ajouts (produits, collections, articles). Il liste les URLs canoniques utiles à l’indexation et n’inclut pas les variantes produit ni la recherche interne ; c’est voulu pour limiter les doublons. L’intérêt n’est pas d’“imposer” l’indexation, mais de guider la découverte des contenus prioritaires.
Soumettez le sitemap dans la Search Console, vérifiez les exclusions et, surtout, renforcez la qualité côté site : retirer les pages faibles et stabiliser les canoniques a plus d’impact que “bricoler” le sitemap.
robots.txt : comportement par défaut et ajustements via robots.txt.liquid
Par défaut, Shopify restreint ce qui doit l’être (admin, panier) et laisse explorer le contenu public. La personnalisation via robots.txt.liquid sert à canaliser le crawl lorsqu’une arborescence génère des URLs peu utiles (recherche interne, tri, certaines facettes).
Exemple :
User-agent: * + Disallow: /search pour éviter que les résultats de recherche interne diluent le budget de crawl.
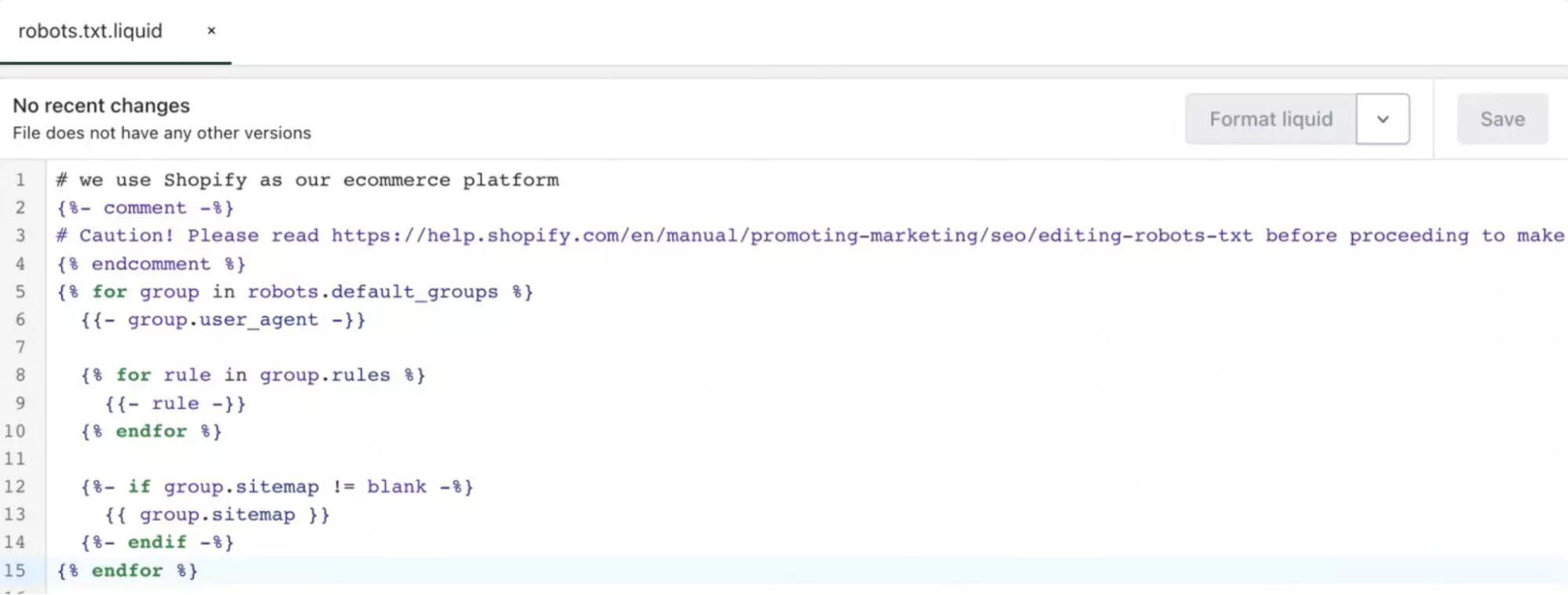
Important : robots.txt n’efface pas l’indexation passée et ne remplace pas un noindex quand vous voulez retirer une page déjà connue ; c’est un signal de crawl, pas un bouton d’index.
Fil d’Ariane, redirections 301 et performances d’infrastructure
Le fil d’Ariane (breadcrumb) structure la compréhension thématique : l’utilisateur retrouve où il se trouve, et le moteur lit mieux la hiérarchie catégories/produits. Les redirections 301 sont proposées automatiquement lors d’un changement de slug ; elles préservent l’équité de liens, à condition d’éviter les chaînes (301 → 301 → 200) qui ralentissent et diluent les signaux. Côté performance, l’infrastructure mutualisée et le CDN de Shopify offrent une base solide pour les Core Web Vitals ; votre marge de progression se joue surtout dans la frugalité JS/CSS du thème et des apps.
International avec Shopify Markets : répertoires, hreflang automatique, limites

Shopify Markets facilite l’international via des sous-répertoires (ex. /fr/, /en/) et génère les balises hreflang (signalant les versions linguistiques/régionales). C’est propre pour le SEO : on consolide l’autorité sur un même domaine et on oriente chaque marché vers sa bonne version. Les limites viennent de la gouvernance : prix, stock, messages légaux peuvent diverger par marché et doivent rester synchronisés pour éviter incohérences et duplications involontaires. Évitez aussi les redirections automatiques par IP, car vous risquez de forcer le crawler Google à indexer une version pays qui n’est pas votre marché principale ; préférez un sélecteur de pays/ langue.
Maillage interne et données structurées JSON-LD
Le maillage interne via menus, collections et blocs de recommandations forme des silos thématiques : il aide le lecteur à progresser et le moteur à relier les sujets proches.
Côté données structurées, Shopify embarque du JSON-LD produit de base, souvent suffisant pour déclencher des rich results (prix, disponibilité, avis). La clé reste la cohérence : une seule source de vérité (thème ou app), des identifiants propres (GTIN/MPN), et une vérification régulière dans la Search Console et l’outil de test des résultats enrichis.
Limites et impacts directs sur le SEO Shopify
Shopify est un socle solide, mais son modèle plateforme-as-a-service impose des garde-fous qui influencent la stratégie SEO. Mieux vaut les connaître pour les contourner intelligemment plutôt que de les subir.
Accès serveur restreint : ce que cela change vraiment
Dans un environnement fermé, vous n’accédez pas aux logs serveur bruts. Or ces journaux décrivent, requête par requête, le comportement réel des robots (fréquence, profondeur de crawl, erreurs). Sans eux, l’audit post-refonte devient plus inférentiel qu’observé. On se repose davantage sur des proxys d’information : Crawl Stats et rapports d’exploration de la Search Console, métriques RUM côté navigateur, et recrawls comparatifs au crawler.
La conséquence stratégique : il faut planifier la preuve (avant/après) — crawls de référence, suivi des erreurs, tests de redirection — pour isoler les anomalies de structure qui freinent le crawl. Autrement dit, on compense l’absence de logs par une méthodologie de mesure rigoureuse, et comparative avant/après. Cependant si le crawler Google se perd dans les méandres de votre site, difficile de savoir où sans accéder aux logs.
Vous n’avez pas accès à votre .htaccess.
Ce document est parfois d’importance vitale pour le SEO, parce qu’il définit certaines consignes aux robots d’exploration des moteurs de recherche, consignes qui sont impératives. Sans possibilité de modifier ce fichier, vous perdez un levier important pour votre référencement naturel.
Ce problème est particulièrement sensible lorsque vous utiliser beaucoup la navigation par facettes sur le site, et que vous souhaitez éviter au maximum l’indexation de pages en duplicate par les moteurs de recherche.
Si vous êtes un e-commerçant averti des problématiques SEO, vous aurez tendance à répondre que ce type de problème peut être résolu via la mise en place des balises canonicals.
C’est en partie faux, car malheureusement les déclarations de canonicals sur une page ne sont pas une consigne impérative pour le Google Bot. Il s’agit d’une indication uniquement, dont le respect se fait à la discrétion de Google.
Bien souvent en testant vos urls dans Google, vous trouverez que plusieurs pages similaires sont indexées par le moteur, ce qui est particulièrement néfaste pour votre référencement naturel, et disperse votre budget crawl sur des urls sans intérêts SEO.
Structure d’URL imposée : ce que le /products/ change pour le sens
La syntaxe d’URL est très cadrée : produits sous /products/, collections sous /collections/. Par défaut, la page produit ne reflète pas l’arborescence des catégories ; elle ne « vit » pas dans /collections/…/produit. Résultat : la sémantique portée par l’URL est plus faible qu’avec des sous-niveaux riches (catégorie → sous-catégorie → produit), et le siloing thématique ne peut pas s’appuyer sur l’URL seule. Ce n’est pas bloquant si vous renforcez le maillage interne et le fil d’Ariane : ces deux signaux racontent à Google la relation entre collections et produits. En pratique, pensez l’architecture comme un graphe de liens explicites (navigation, blocs “produits associés”, chemins retour vers la collection), plutôt qu’un arbre profondément encastré dans les chemins d’URL.
À retenir : l’URL ne fait pas tout. Sur Shopify, c’est le schéma des liens (et la cohérence des gabarits) qui porte le sens.
Paramètres de variantes (?variant=) : consolider sans s’enfermer
Les variantes (taille, couleur) génèrent des paramètres d’URL. Shopify place généralement un canonical vers l’URL produit “propre”, ce qui évite de multiplier des pages quasi identiques. L’intention SEO est claire : consolider tous les signaux sur une page de référence. Faut-il pour autant bloquer ces paramètres au robots.txt ? Attention au contre-effet : si un robot ne peut plus explorer une URL paramétrée déjà connue, il risque de conserver une version obsolète en index sans voir le canonical. La logique moderne consiste à :
- laisser le canonical faire son travail,
- éviter de mailler massivement les variantes,
- n’ouvrir qu’exceptionnellement une variante sémantiquement distincte (vrai contenu spécifique, intention de recherche propre).
Le robots.txt peut rester un garde-fou pour limiter l’exploration massive, mais il ne remplace ni le canonical ni, le cas échéant, un noindex servi sur la page.
Filtres et facettes : quand la puissance devient duplication
L’app de filtres (Search & Discovery) et les tris (sort_by) créent des combinaisons paramétrées qui se ressemblent fortement. À l’échelle, cela génère des pages proches, dilue les signaux et perturbe la découverte de ce qui compte vraiment. La bonne approche n’est pas « tout bloquer par principe », mais hiérarchiser :
- quelles facettes ont une vraie demande de recherche et méritent une URL stable (avec self-canonical, contenu descriptif, maillage) ?
- lesquelles n’apportent rien au moteur et doivent rester fonctionnelles mais non indexées (ou ramenées vers la collection de base via canonical) ?
La clé est de séparer navigation et indexation : la première aide l’utilisateur, la seconde doit rester sélective.
Impacts SEO Shopify « indirects »
Le contenu n’explique pas tout. Les performances, les tags marketing et la mesure façonnent eux aussi la visibilité. Ce sont des chantiers non-contenu à fort effet de levier.
Dette JS/CSS des apps et thèmes : pourquoi l’INP trinque
Chaque app ajoute des scripts et des feuilles de style. Isolément, l’impact paraît minime ; cumulés, ces fichiers saturent le thread principal du navigateur, retardent la réponse aux interactions et dégradent l’INP (Interaction to Next Paint). L’utilisateur le ressent : clics qui « collent », menus qui réagissent tard. Le moteur le mesure aussi. La bonne question n’est donc pas “quel script supprimer” mais “quel travail de calcul éviter au premier rendu”. Cela passe par une frugalité assumée : charger seulement ce qui est nécessaire pour la première impression, différer le reste, supprimer les reliquats d’apps retirées, et traiter images/CSS avec les formats et priorités adaptés. Moins de JS exécuté au first view signifie une page qui répond plus vite, un crawl plus simple, et des signaux de qualité qui remontent.
Gouvernance des tags (GTM) : du « tout mesurer » au « mieux mesurer »
Un conteneur GTM trop riche devient souvent le script dominant du chargement. Au-delà du poids réseau, chaque tag ajoute des exécutions et des écoutes d’événements qui se cumulent avec le code du site. La gouvernance sert à choisir ce qui mérite d’être mesuré et où. Un principe simple : un pixel, une finalité. Pas de doublons. Déclenchez là où l’intention existe (remarketing sur fiches produit, conversion sur page de remerciement), pas sur « All Pages » par défaut. Priorisez et déclenchez plus tard ce qui peut l’être, bloquez les fournisseurs trop gourmands, et activez le Consent Mode pour éviter des appels inutiles. L’enjeu n’est pas d’appauvrir la donnée, mais de la rendre plus signal que bruit, sans hypothéquer les Web Vitals.
Analytics & attribution : quand les paramètres racontent une fausse histoire
Les URLs à paramètres (tris, filtres, ?variant=, UTM) produisent des doublons analytiques : une même page d’intention se retrouve éclatée en plusieurs lignes de rapports GA4. On croit piloter finement, on perd en lisibilité. Côté SEO, ces mêmes variantes peuvent créer un duplicate inutile si elles se laissent indexer. La réponse tient en trois leviers complémentaires :
- Normaliser l’URL de référence via canonical systématique vers la version propre.
- Cadrer la facette : n’indexer que ce qui porte une intention, et retirer de l’index ce qui n’en a pas (meta noindex ou canonical vers la collection de base).
- Nettoyer la mesure : exclure les paramètres non analytiques dans GA4, éviter les self-referrals, et s’assurer qu’un seul flux d’événements d’achat alimente vos conversions.
Un dernier rappel utile : robots.txt régule le crawl, pas l’indexation. Bloquer sans stratégie peut figer de mauvaises versions en index. Faites coïncider directives techniques et objectif métier.
Faqs
Comment bien référencer son site Shopify ?
Pour bien référencer un site Shopify, il faut travailler à la fois le contenu, l’optimisation on-page et la technique. Concrètement, commencez par configurer Google Search Console, soumettre le sitemap, puis optimiser chaque page avec un titre descriptif, une méta-description, un H1 clair et des textes alternatifs pertinents. Shopify gère déjà certains éléments techniques, comme les balises canoniques, le robots.txt et le sitemap.xml, mais la qualité du contenu et la structure des pages restent déterminantes.
Comment rendre visible sa boutique Shopify ?
Pour rendre visible votre boutique Shopify, il faut d’abord s’assurer qu’elle peut être explorée et indexée par Google. La première étape consiste à connecter la boutique à Search Console, soumettre le plan du site et vérifier que vos pages importantes apparaissent bien dans l’index. Ensuite, publiez des fiches produits, collections et contenus éditoriaux utiles, avec des titres et descriptions précis, afin d’aider les moteurs à comprendre votre offre et les internautes à cliquer.
Comment booster mon site Shopify ?
Pour booster un site Shopify, il faut prioriser les actions à plus fort impact : connecter Search Console, soumettre le sitemap, contrôler l’indexation, améliorer les titres, méta-descriptions, H1 et images, puis enrichir les fiches produits et les pages collections avec un contenu plus utile et plus précis. Shopify fournit déjà une base technique solide sur plusieurs points, mais la progression vient surtout d’un meilleur contenu, d’une architecture claire et d’un travail continu sur la visibilité externe.
Améliorez vos connaissances
en webmarketing Digital
Stratégie et techniques d’acquisition en SEA, SEO et sur les réseaux sociaux. Reussissez vos synergies cross canal. AEP Digital vous propose des conseils pour réussir votre stratégie webmarketing